Accounting for Model Drift
 Image credit: Karol Smoczynski
Image credit: Karol Smoczynski
To improve forecasting capability during uncertain times it is necessary to both understand and address model drift. The hypothesis I aim to test is that electricity consumption forecasts will be more prone to errors in states that have seen more severe and prolonged restrictions as a result of COVID-19.
Using daily electricity consumption for Vic, NSW, Tas, SA, and QLD this blog will demonstrate:
- What model drift is.
- The importance of using train, development, and test splits.
- The estimated operational performance of day ahead forecasts using MLP ANN’s.
- Model drift in an operational setting.
- That tracking model performance and regularly re-training models, errors can be reduced by an average of 8.15%.
What is model drift?
Model drift is the degradation of forecasting capability over time. One method to tackle this problem is to re-train forecasting models. By scaling the errors for each forecasting model to 100 we can track how each model drifts.

Key takeaway messages from tracking model development include:
- Drift occurs slowly. There is a small increase in errors as the model progressively makes predictions on development and test data.
- Relative errors fluctuate around 100 during the training period.
- Model drift can be used to indicate how our model is likely to perform further into the future.
At this point it is essential to ask “what causes model drift?"
The cause of model drift and importance of train, dev, test splits.
Model drift results from using a forecasting model that was developed using one data set to make forecasts for a data set with different statistical properties. This commonly occurs when we make forecasts in uncertain or unprecedented times.
To make reliable forecasts it is necessary to develop models using training, development, and test sets.
- The training set is used to update model parameters and assess performance when the model has seen the data.
- The training and development sets are used to tune hyper-parameters. 3.The test set is used to assess performance on a data set the model has not seen.
Using a scaled density plot we can visualise the cause of model drift and importance of train, dev, test splits.
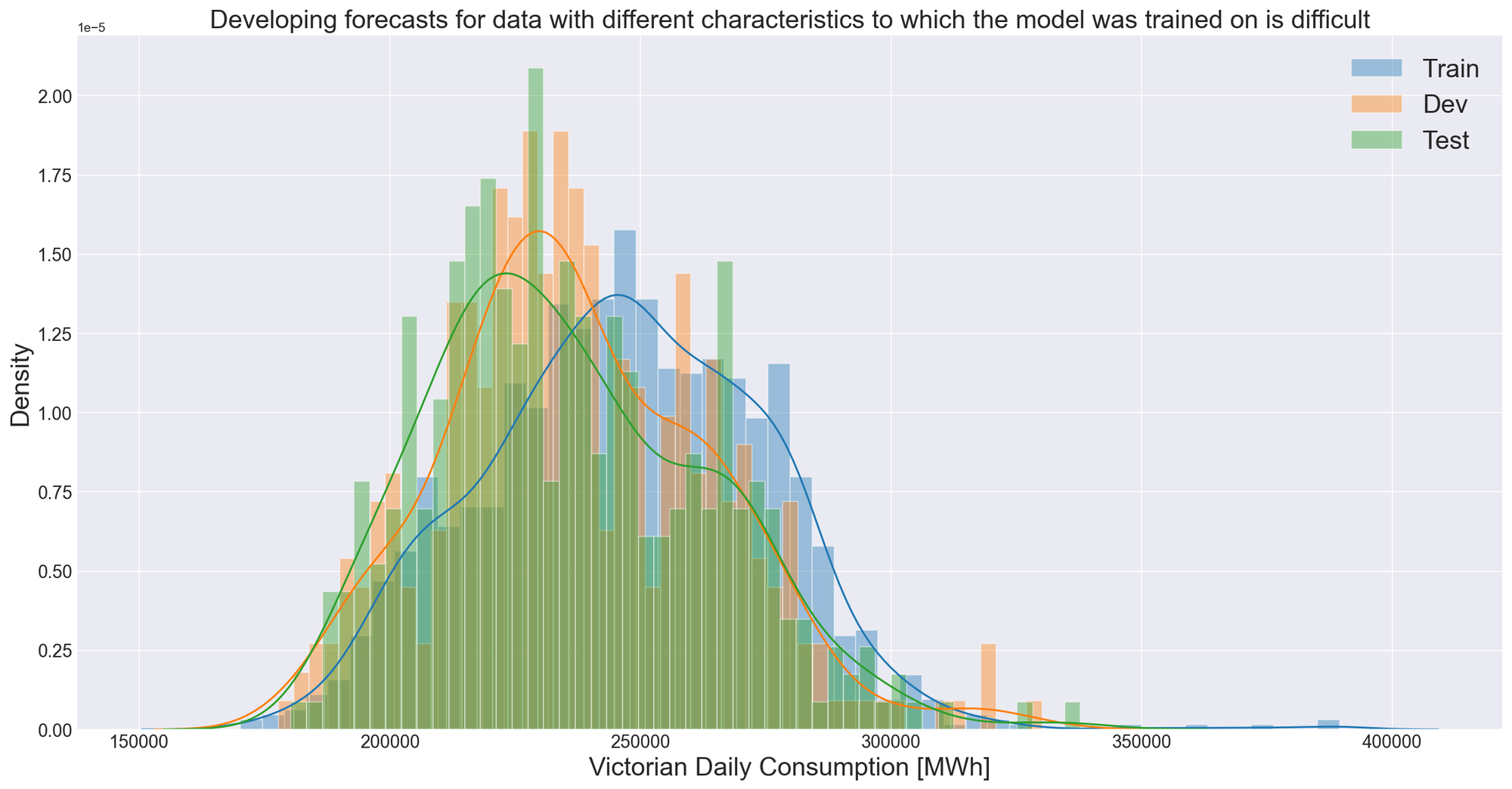
Key takeaway messages from reviewing the scaled density plots for Victoria include:
- The density function for each data set is significantly different.
- If only a train and test set are used then there is no way to assess performance on an unknown data set.
- We are likely to see model drift in the Dev and Test sets.
Estimating operational performance of MLP ANN’s to predict electricity consumption.
The train and development sets were used tune hyper-parameters. A 6-neuron layer and Dropout of 8% were used to avoid over-fitting. Using the test set we can now estimate model performance in an operational setting.
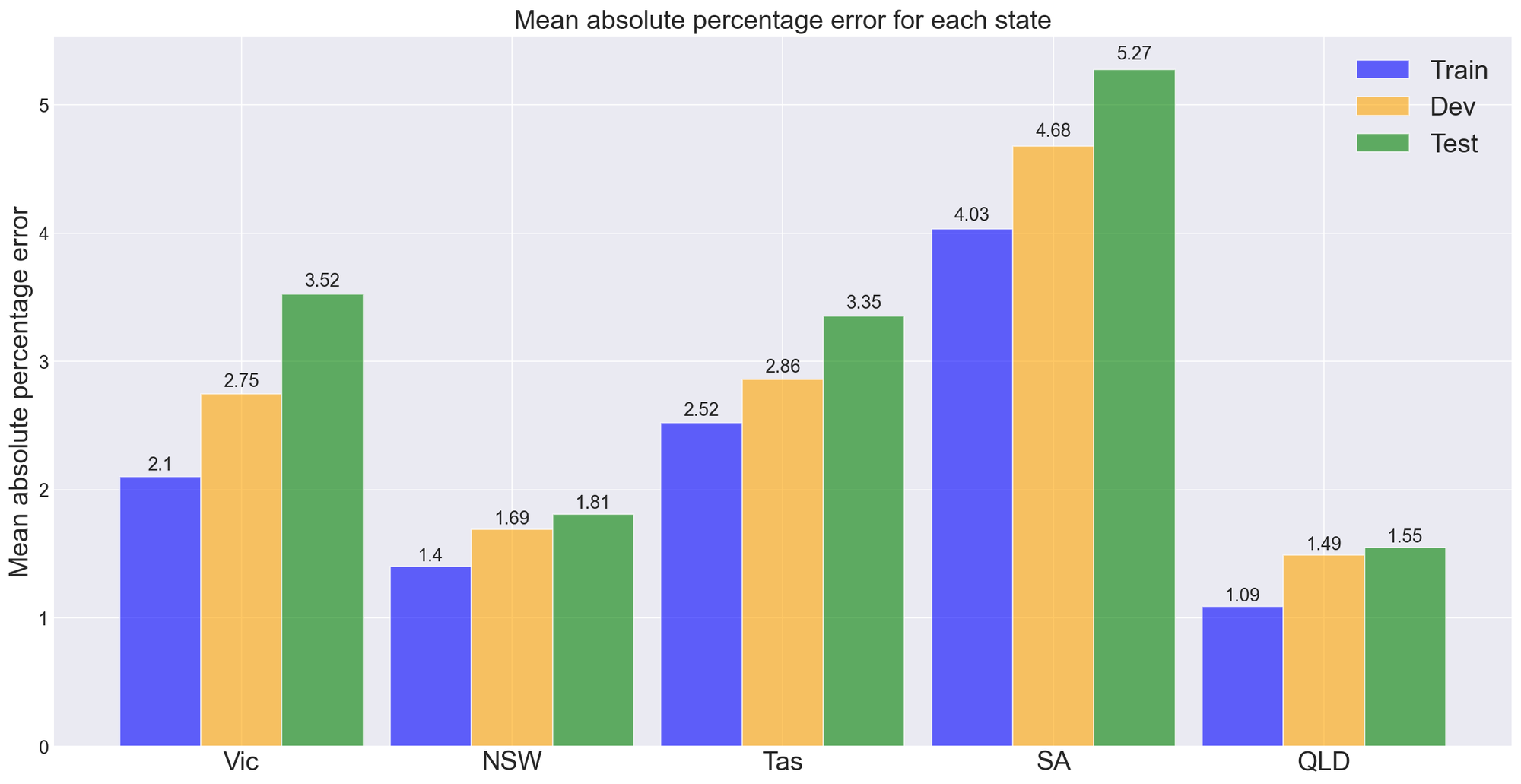
Key takeaway messages from reviewing model performance in each state include:
- Model performance using the test set is indicative of operational performance.
- Models perform best using the training data set.
- States that consume more electricity have lower mean absolute percentage errors, this is a result of the error metric used.
Model drift in an operational setting.
Prior to making operational forecasts it is now wise to take advantage of all the data available and re-train the model.
Using 2020 as a forecast year we can now test the initial hypothesis that states which have seen more severe and prolonged restrictions as a result of COVID-19 will be more prone to errors.
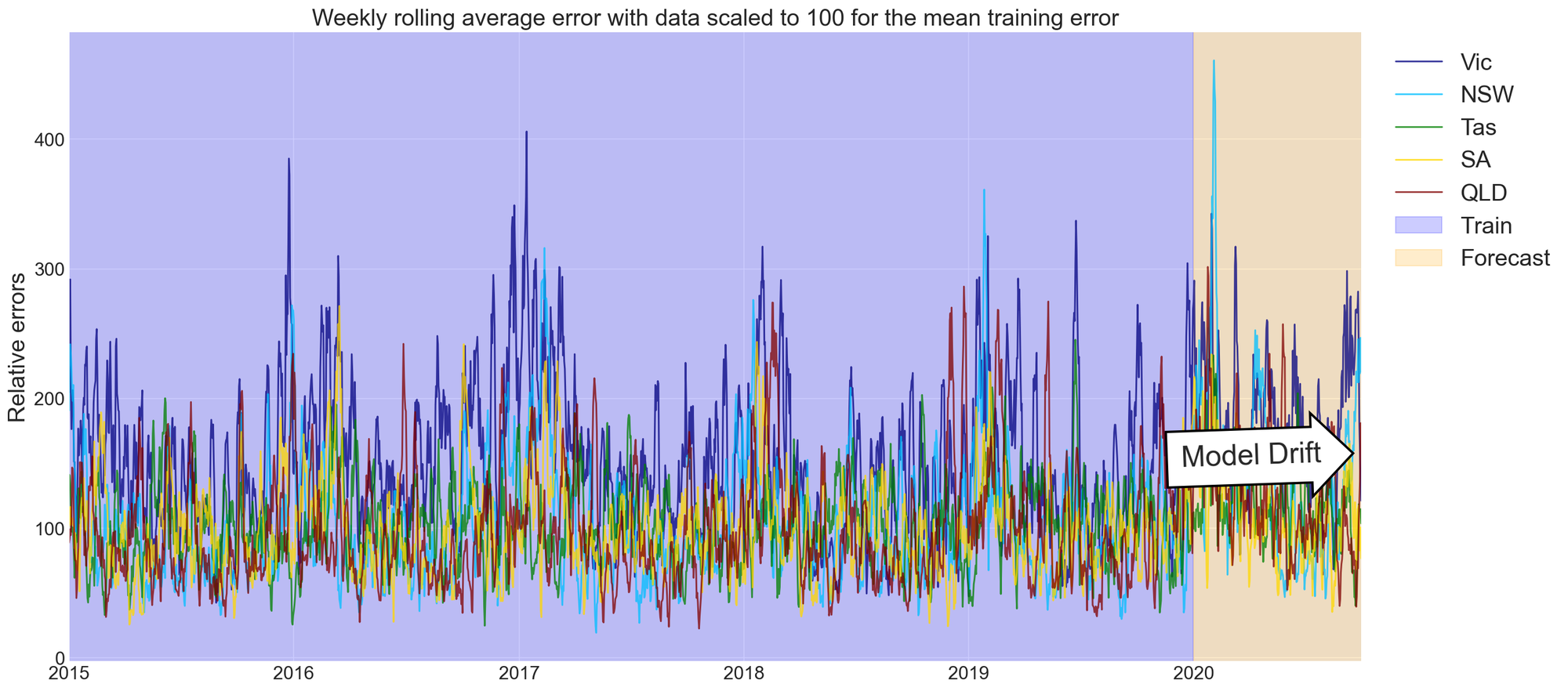
The key takeaway messages from reviewing model performance are:
- Victorian electricity consumption forecasts tend to drift more than others. Is this a result of tighter restrictions?
- Errors tend to have a seasonal component; this indicates further improvements can be made to the model and that we cannot assume a jump in errors is caused by tighter restrictions.
- More pronounced changes may be observable at the 30 min timescale.
Reduction in operational forecast errors by tracking model performance and re-training models.
As the scale of the model grows both the resources required and the time taken to re-train models need to be weighed against the end-user’s tolerance for error.
Using data up until the start of September 2020 we can now re-train our models and estimate the value gained by re-training the models instead of leaving them to drift.
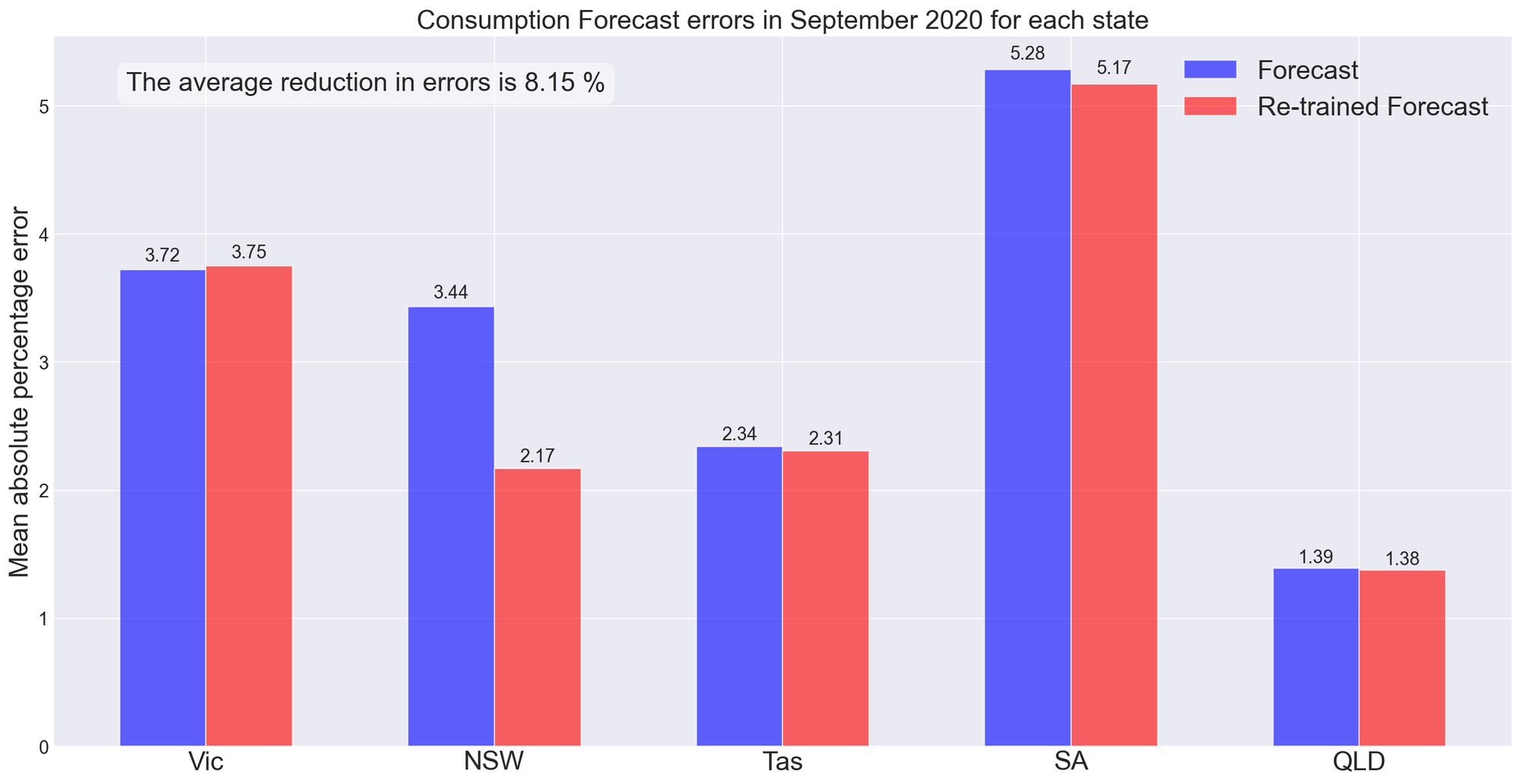
The key takeaway messages from reviewing model performance for each state in September 2020 include:
- By tracking model drift and re-training our models, reductions in operational forecast errors of 8.15% can be realised.
- A reduction of errors is not guaranteed.
- Operational performance is similar to that estimated earlier.
Summary
I have provided an overview of one way to track and account for model drift. Following this procedure allows end-users to track operational model performance and schedule re-training when a desired threshold is met.
We tracked model drift using 2020 electricity consumption data. It is not entirely clear if the increase in model errors can be attributed to restrictions put in place to combat COVID-19. Developing forecast models at greater resolution may provide more insights.
Ashley Wright
Research Fellow
These blog posts are exploratory only and should not be considered as advice.